
JDK의 디폴트 Garbage Collector(이하, GC)인 G1 GC는 JDK-14때부터 JEP-345: NUMA-Aware Memory Allocation for G1 에 의해 NUMA-aware하게 되었습니다1. 이 글에서는 일반적인 G1 GC 구현에 대한 언급과 함께 NUMA-aware 구현에 대해 간단히 설명할 예정입니다.
NUMA 란?
시작하기에 앞서, NUMA가 무엇인지 상기해 보겠습니다.
NUMA는 Non-Uniform Memory Access의 약자이며 프로세스에게 있어서 로컬 메모리 액세스가 로컬이 아닌 메모리 액세스보다 빠르다는 것입니다. 이 경우 최대한 로컬 메모리를 쓰도록 최적화 해야 겠지요. 프로세스와 로컬 메모리를 노드라고 합니다.
참고로 사용중인 2 소켓 워크스테이션, Xeon E5-2665 2.4GHz에서 로컬 메모리 액세스 시간은 로컬이 아닌 메모리 액세스 시간의 61.98%만 걸립니다.2.
일반적으로 NUMA-awareness를 추가하게 되면 어느 정도의 성능 향상을 기대합니다3. 따라서 Parallel GC는 JDK-6 update 릴리즈에 NUMA-aware를 추가했고 ZGC는 처음부터 NUMA-awareness를 염두에 두고 개발 되었습니다.
그렇다면 NUMA-aware 구현 전에는?
G1 GC 알고리즘은 JEP-345에 의해 NUMA-aware하게되기 이전에도 NUMA 노드간에 메모리를 인터리빙(interleaving)했습니다. 이것은 메모리가 활성화된 NUMA 노드들로부터 균일하게 분배되고 라운드 로빈 방식으로 할당됨을 의미합니다. 즉, 우리는 UseNUMA를 활성화 했다면, 이미 메모리 인터리빙으로 인한 성능 향상을 얻고 있었습니다4. 따라서 NUMA-aware 구현으로 인한 성능 향상만을 비교하려면, 패치 전 및 패치 후에 -XX:+UseNUMA를 추가해야합니다.
NUMA-aware: 힙 초기화
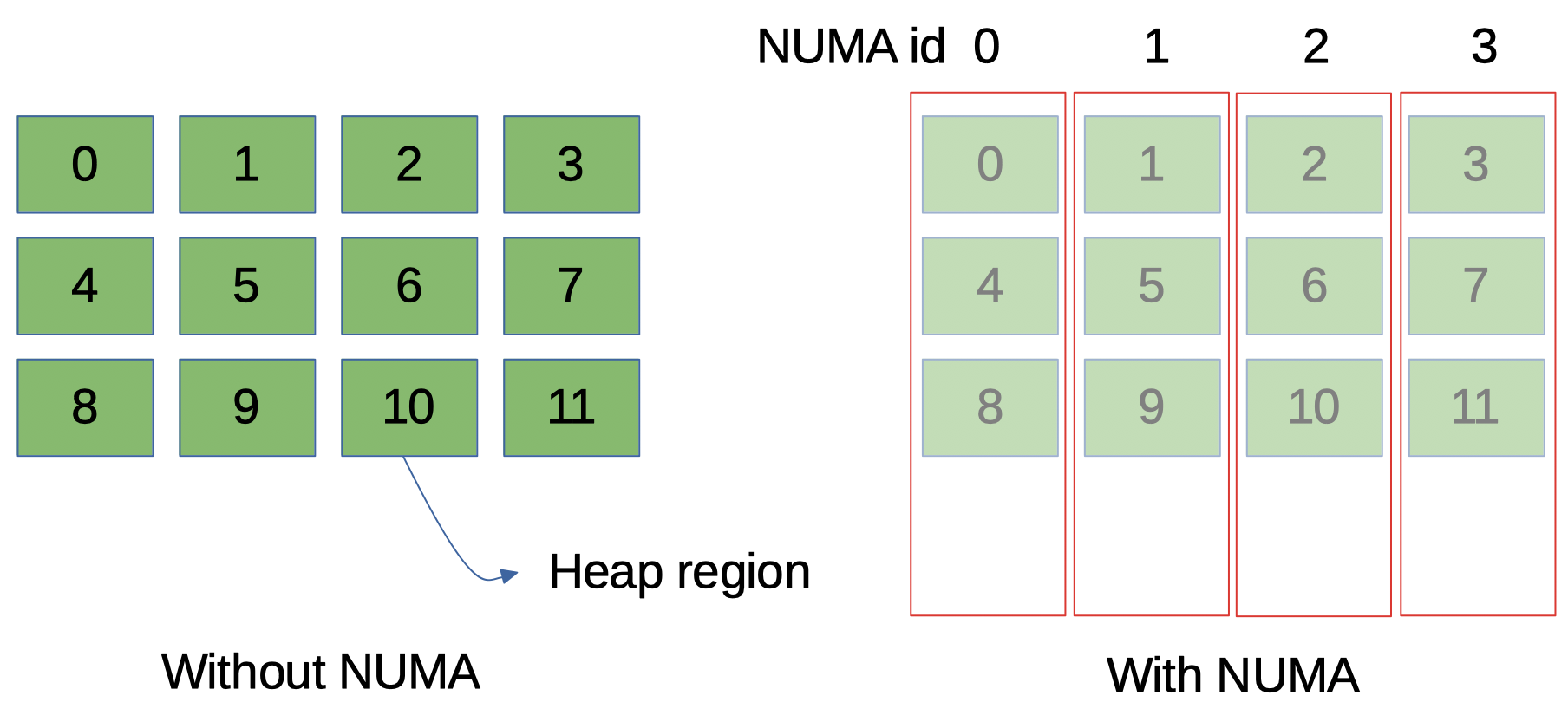
G1 GC는 Java 힙을 동일한 크기의 여러 청크(chunk)로 분할 한 후 관리하며 각 청크를 G1 heap region이라고합니다 (내부적으로 HeapRegion 혹은 G1HeapRegion이라고 부르므로 G1 heap region이라고 하겠습니다). NUMA 를 활성화한 Java 힙 초기화 시에는 OS에 정해진 NUMA 노드에 각각의 G1 heap region을 할당하도록 요청하는 것입니다. 여기서 정해졌다는 것은 현재 활성화된 NUMA ID를 G1 heap region에게 균등하게 할당하는 것을 의미합니다. 이 할당 요청은 OS에 의해 정상적으로 처리되어 전체 힙이 활성 NUMA 노드 사이에 균등하게 위치한다고 가정합니다. (그림 1)
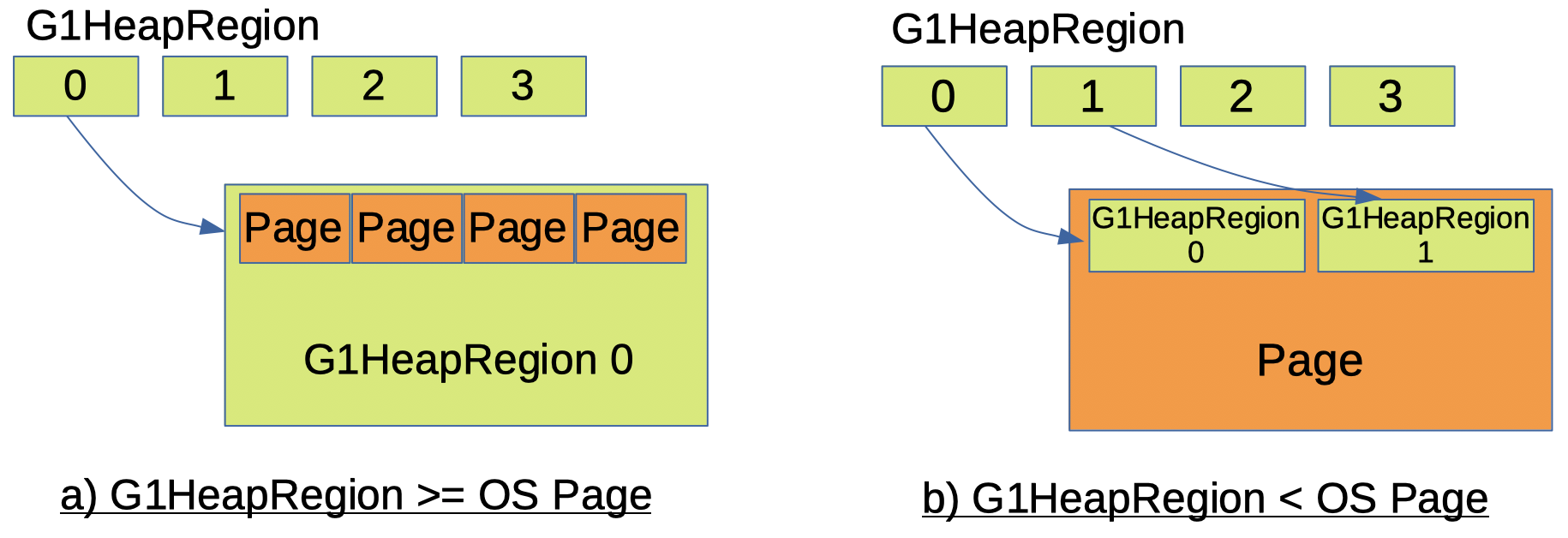
이제 G1 GC heap region이 OS 페이지를 처리하는 방법에 대해 알아보겠습니다. G1 GC에서 NUMA ID의 단위는 heap region입니다. 즉, 하나의 heap region, 하나의 덩이리는 동일한 NUMA ID를 갖는 것으로 간주됩니다. 그리고 이것은 OS의 NUMA 할당 단위인 페이지(page)와는 다릅니다. OS 페이지가 G1 heap region 크기보다 작으면 구현은 간단합니다. 하나의 G1 heap region은 여러 OS 페이지로 구성됩니다. 예 : G1 heap region 크기가 1MB이고 페이지 크기가 4KB이면 1 개의 heap region에 256 페이지가 사용됩니다. G1 heap region 크기가 OS 페이지 크기보다 작으면 어떻게 될까요? 이 경우 하나의 페이지가 여러 개의 G1 heap region에 사용됩니다. 예 : G1 heap region 크기가 1MB이고 페이지 크기가 2MB 인 경우 2 개의 heap region에 1 페이지가 사용됩니다 (그림 2). 물론 G1 heap region 크기와 OS 페이지 크기의 경우 한 크기가 다른 크기의 배수여야 합니다.
NUMA-aware: 메모리 할당
힙 초기화가 되었으니, 이제 어떻게 메모리가 Java 애플리케이션에 할당되지에 대해 알아보겠습니다.
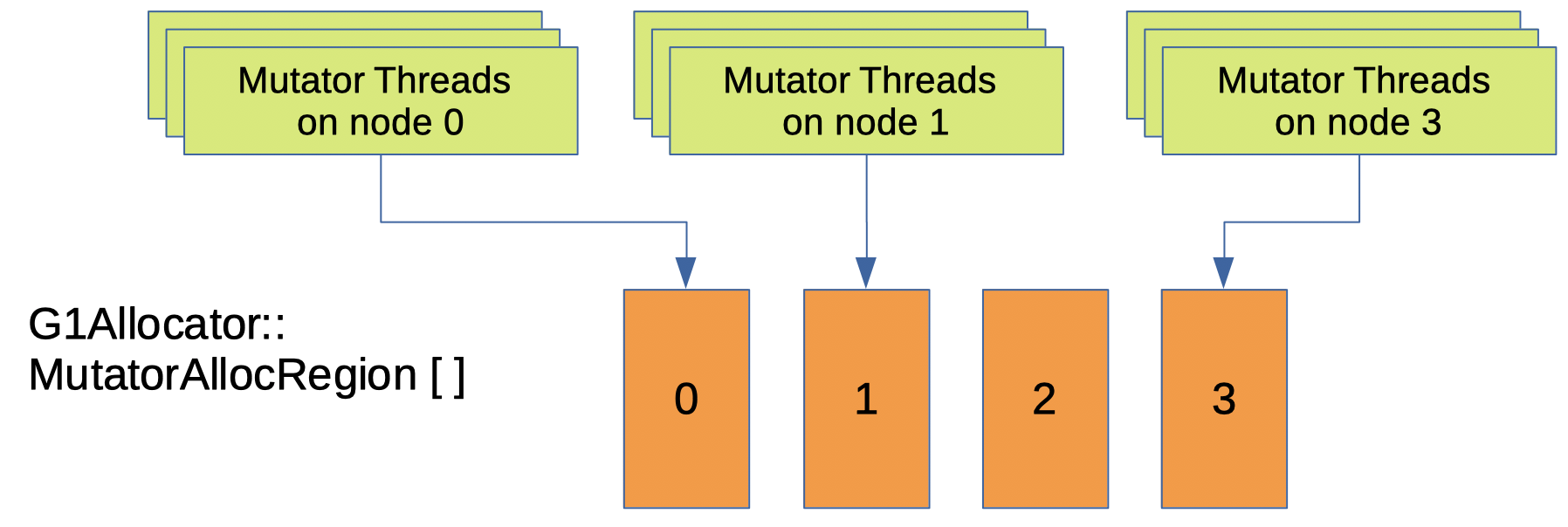
NUMA-aware 구현 전에는 Java 쓰레드가 JVM에 메모리를 요청하면 G1 GC는 단일 MutatorAllocRegion 인스턴스에서 메모리를 할당합니다5.
NUMA-aware 구현에서의 G1 GC는 여러 MutatorAllocRegion 인스턴스를 가지고 있습니다 - NUMA 노드 당 1 개의 인스턴스 (그림 3).
따라서 Java 쓰레드가 JVM에 메모리를 요청하면 G1 GC는 mutator (Java 쓰레드)의 NUMA 노드를 확인한 다음 동일한 NUMA 노드를 가진 MutatorAllocRegion에서 메모리를 할당합니다.
NUMA-aware: Young Evacuation중 살아남은 오브젝트들 할당
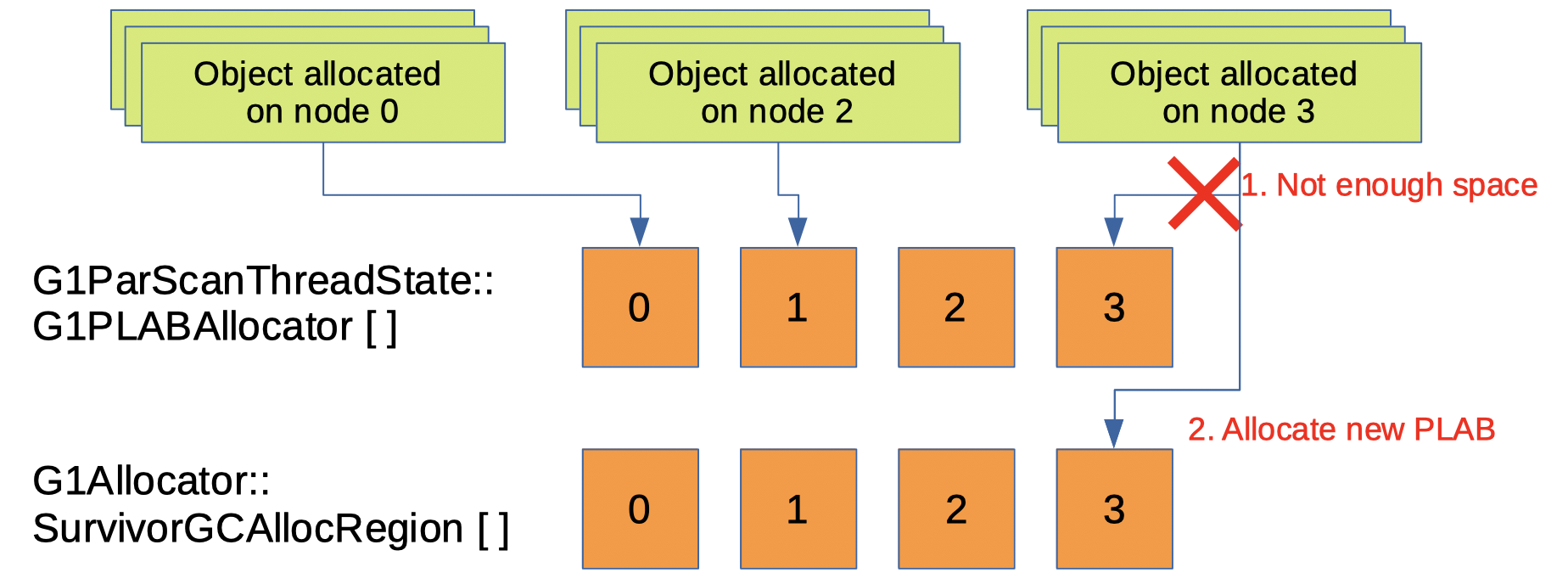
위의 개념은 Survivor region에서도 동일합니다. G1 GC에는 여러 SurvivorGCAllocRegion이 있고, NUMA 노드 당 1 개의 인스턴스가 있습니다. 다만, MutatorAllocRegion과는 다르게 고려해야 할 다른 사항이 있습니다. 그것은 G1 GC가 살아남은 오브젝트들을 복사할때 쓰는 버퍼인데, PLAB(Promotion Local Allocation Buffer)라고 합니다.
Young GC가 발생하면, G1 GC는 살아남은 오브젝트들을 survivor region에 복사할 때, 여러개의 GC 쓰레드에서 하게됩니다6. 각각의 GC 쓰레드는 이 복사 작업을 고유의 PLAB에서 수행합니다. 각각의 PLAB은 같은 NUMA 노드를 가진 SurvivorGCAllocRegion에서 할당됩니다. PLAB의 사용으로 SurvivorGCAllocRegion에서 직접 메모리를 할당 받는 경우에 비해 동기화를 최소화 할 수 있습니다. 이처럼 두 가지를 구현함으로써 younge evacuation중 살아남은 오브젝트들의 메모리 할당은 NUMA-aware하게 되었습니다.
No NUMA-aware Processing for Old Generation
처음에 전체 Java 힙이 활성 NUMA 노드로 균등하게 분할 될 것이라고 언급했지만 young generation (Eden 및 Survivor region) 만 설명했습니다. G1 GC는 나머지인 Old generation을 처리할 때 NUMA 노드 정보를 활용하지 않습니다.
현재 Old generation은 heap region을 NUMA 노드 정보 없이 특정 리스트의 head 부분에서 받습니다7. 즉, 한 개의 OldGCAllocRegion 인스턴스가 있으며, 이것은 NUMA 구현 이전과 동일합니다. 그리고 NUMA 노드와 상관없이 할당 받음으로써 heap region의 로드 밸런싱에도 도움이 됩니다.
사실 구현할 때, NUMA 노드 정보를 계속 유지 하는 방법도 있었습니다. 즉, 살아남은 오브젝트들을 복사할 때, 해당 오브젝트의 NUMA 노드대로 복사를 하는 것인데, 이럴 경우 특정 노드가 많이 소비되는 문제(밸런싱)가 있었습니다. 또한 성능 향상도 없었기에 채택하지 않았습니다. ParallelGC에 NUMA-aware를 추가할 때에도 성능 향상이 없어서 Old generation은 NUMA-aware하게 처리하지 않습니다.
추후에라도 가시적인 이점이 있다면 old generation도 NUMA-aware 하도록 변경 할것 입니다.
로그 메시지
새로 추가된 NUMA-aware 구현은 numa 로그 태그에 속합니다. -Xlog:gc*로 로그를 프린트할 경우, NUMA의 info 레벨 로그도 프린트됩니다. 그리고 NUMA관련 로그만 보고 싶다면, -Xlog:numa*={log level}로 하면 됩니다.
SpecJBB2015 결과 비교
이제 구현 결과, 성능이 얼마나 향상되었는지 확인해 봅시다. 테스트는 SpecJBB2015로 했습니다8. NUMA 구현 (JEP-345)은 JDK-14 빌드 24에 포함되어 있으므로 빌드 23과 비교했습니다. 이 외에도, 2 개의 테스트 결과를 포함했습니다. 최신 LTS (Long Term Support)인 JDK-11과 가장 최신인 JDK-15입니다.
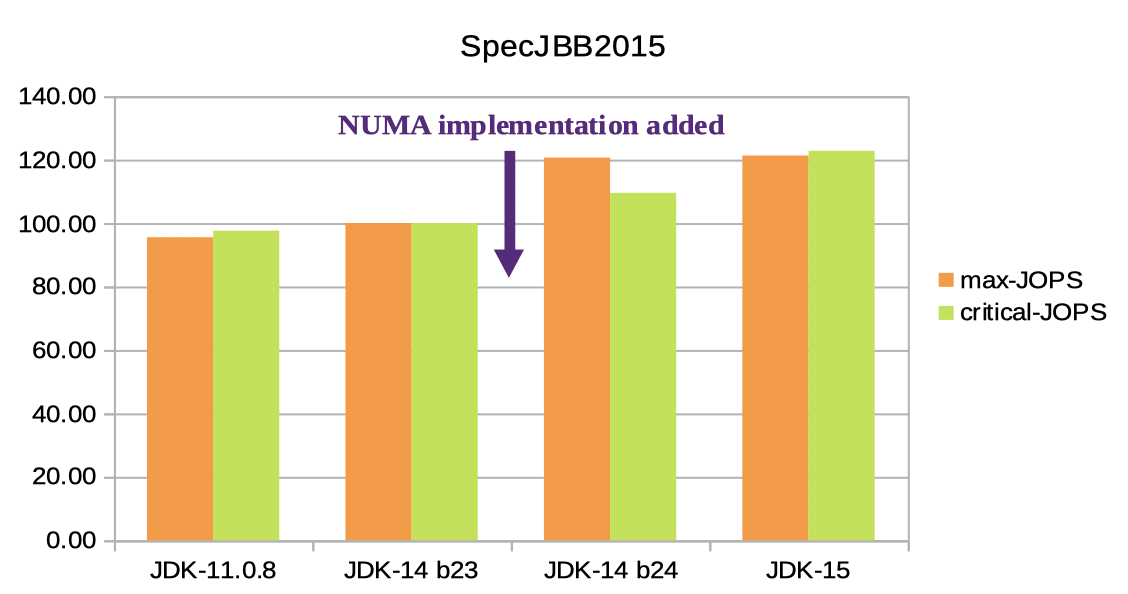
모든 실행은 512GB Java 힙 크기와 4 개의 NUMA 노드 시스템에서 활성화 된 UseNUMA 옵션으로 테스트되었습니다9.
Max-jOPS와 Critical-jOPS 모두 JDK-14 b23과 JDK-14 b24 사이에 확실한 성능 향상을 보여주었습니다. Max-jOPS는 20.64 %, Critical-jOPS는 9.52 % 향상되었습니다. (Max-jOPS와 Critical-jOPS란?)
NUMA와는 관련이 없지만 JDK 버전이 올라가면서 Max / Critical-jOPS가 개선되고 있다는 점도 유의해 볼만 합니다.
테스트 시스템에 NUMA 노드가 많을수록 더 많은 개선이 이루어집니다. 고려해야 할 또 다른 사항은 테스트 할 Java 응용 프로그램이 1 개의 NUMA 노드에서 할당하기에 충분한 작은 Java 힙 크기를 설정하는 경우 크게 개선되지 않을 것이라는 것입니다. 이유는 Java 애플리케이션 및 GC 쓰레드의 mutator 쓰레드는 로컬이 아닌 메모리에 거의 액세스하지 않기 때문입니다. 예 : 테스트 컴퓨터가 2 개의 NUMA 노드에 32GB의 메모리를 가진 경우 각 노드에는 16GB의 메모리가 있습니다. Java 애플리케이션이 1GB의 메모리만 사용하는 경우 라면, 모든 메모리는 대부분 1 개의 NUMA 노드에서 할당 될 수 있으므로 성능 향상이 거의 발생 하지 않을 것입니다.
마지막으로!
이 글에서는 G1 GC에 추가된 NUMA-aware 구현에 대해 간단히 설명했습니다. 백문이 불여일견, 이제 직접 NUMA를 테스트 해보는건 어떠 실지요?
업데이트 (2021-03-01)
탐색 깊이 (Search depth)는 지나친 누마 노드 불균형을 막고자 도입했습니다. 그 기능은 힙 영역을 덜 조각화 하며 FreeRegionList 탐색 시간 지연도 덜 만듭니다. 아래 예에서 G1은 노드 1의 메모리를 요청 받았지만, FreeRegionList는 이미 많은 노드 1을 소비했습니다. 그래서 3 세트 (=12 힙 영역 = # of 누마 노드 개수 * 탐색 깊이 상수 = 4 * 3) 의 힙 영역을 찾아본 후에, G1은 더이상 찾기를 멈추고 리스트에서 가장 첫번째 힙 영역을 리턴합니다.
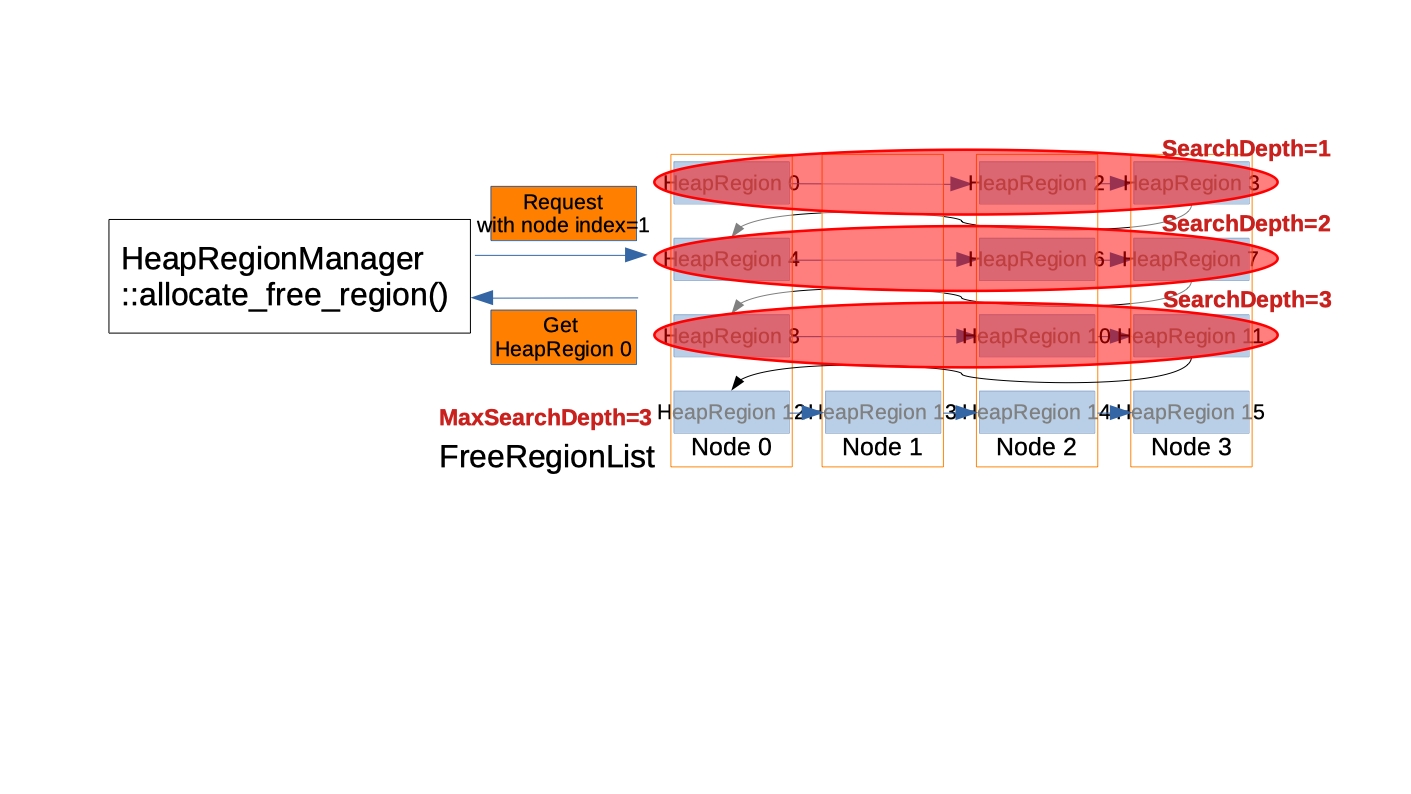
-
리눅스에만 구현됨. ↩
-
numactl --hardware실행시,
node distances:
node 0 1
0: 10 20
1: 20 10Memory Latency Checker v3.5실행시,
Measuring idle latencies (in ns)…
Node 0 1
0 69.7 119.0
1 112.9 69.9 ↩ -
특정 환경에서는 성능 향상이 나타나지 않을 수도 있지만 일반적으로 약간의 성능 향상을 기대할 수 있습니다. ↩
-
UseNUMA옵션을 켤 경우UseNUMAInterleaving옵션은 자동으로 켜지며, NUMA-interleaving은UseNUMAInterleaving으로 제어됩니다. ↩ -
MutatorAllocRegion는 G1 heap region을 위한 클래스. ↩ -
이 GC 쓰레드들은
-XX:ParallelGCThreads={number}옵션에 의해 제어됨. ↩ -
G1 GC의 모든 heap region들은 HeapRegionManager::FreeRegionList에서 할당됨. 그리고 Old generation은 할당시 NUMA 노드 정보를 활용하지 않음. ↩
-
SPEC® and the benchmark name SPECjbb® are registered trademarks of the Standard Performance Evaluation Corporation.
For more information about SPECjbb, see www.spec.org/jbb2015/ ↩ -
Full VM options
-Xmx512g -Xms512g -XX:+AlwaysPreTouch -XX:+PrintFlagsFinal -XX:ParallelGCThreads=48 -XX:ConcGCThreads=4 -XX:+UseG1GC -XX:+UseLargePages -XX:+UseNUMA -Xlog:gc*,ergo*=debug:gc.log::filesize=0 -XX:-UseBiasedLocking↩