
The default Garbage Collector, G1 GC was enhanced on JDK-14 by making its memory allocator NUMA-aware by JEP-345: NUMA-Aware Memory Allocation for G1 1.
In this article, I will explain a little bit about its implementation. I will give minimal explanations about how G1 GC works in general.
What is NUMA?
Before deep diving into it, let’s remind ourselves what is NUMA.
NUMA stands for Non-Uniform Memory Access and in essence says that memory access time depends on the memory location relative to the processor. For a processor, local memory access is faster than non-local memory. In such a system you want to optimize for local memory accesses. The processor and its local memory form a node in a network.
On my 2 socket machine, Xeon E5-2665 2.4GHz, the local memory access time takes 61.98% less than the non-local memory access time2.
Generally, there is no doubt we should expect performance improvement when adding NUMA-awareness to the existing Garbage Collector3. In this regard, Parallel GC added NUMA support since some JDK-6 update and ZGC was developed with NUMA-awareness in mind.
Before NUMA-aware implementation?
G1 garbage collector algorithm interleaved memory among NUMA nodes even before the NUMA-aware implementation was introduced by JEP-345. This means the memory will be evenly distributed over the active nodes and allocated in a round robin fashion when committed. This interleaving already gives us some performance improvements if UseNUMA is enabled4. So when we want to compare performance improvements by the NUMA-aware implementation only, -XX:+UseNUMA should be added for both before the patch and after the patch runs.
NUMA-aware Heap Initialization
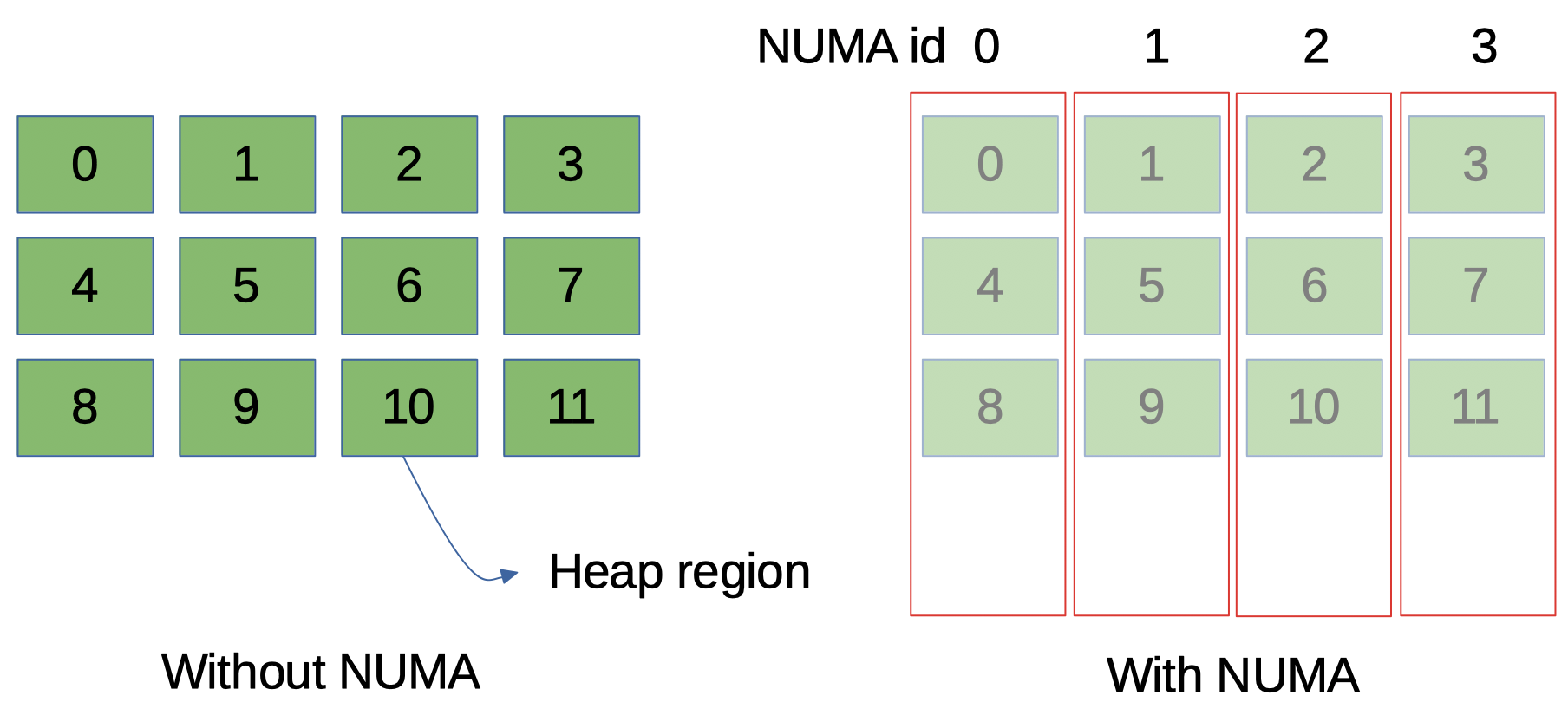
G1 GC manages the Java heap after splitting the Java heap into multiple same-sized chunks and each chunk is called G1 heap region. So what happens during the NUMA enabled Java heap initialization is requesting to OS to locate G1 heap regions on appropriate NUMA nodes. Appropriate here means rotating active NUMA ids on the G1 heap region evenly. We assume the request will be honored by OS and the given whole heap will be located evenly among the active NUMA nodes. (Figure 1)
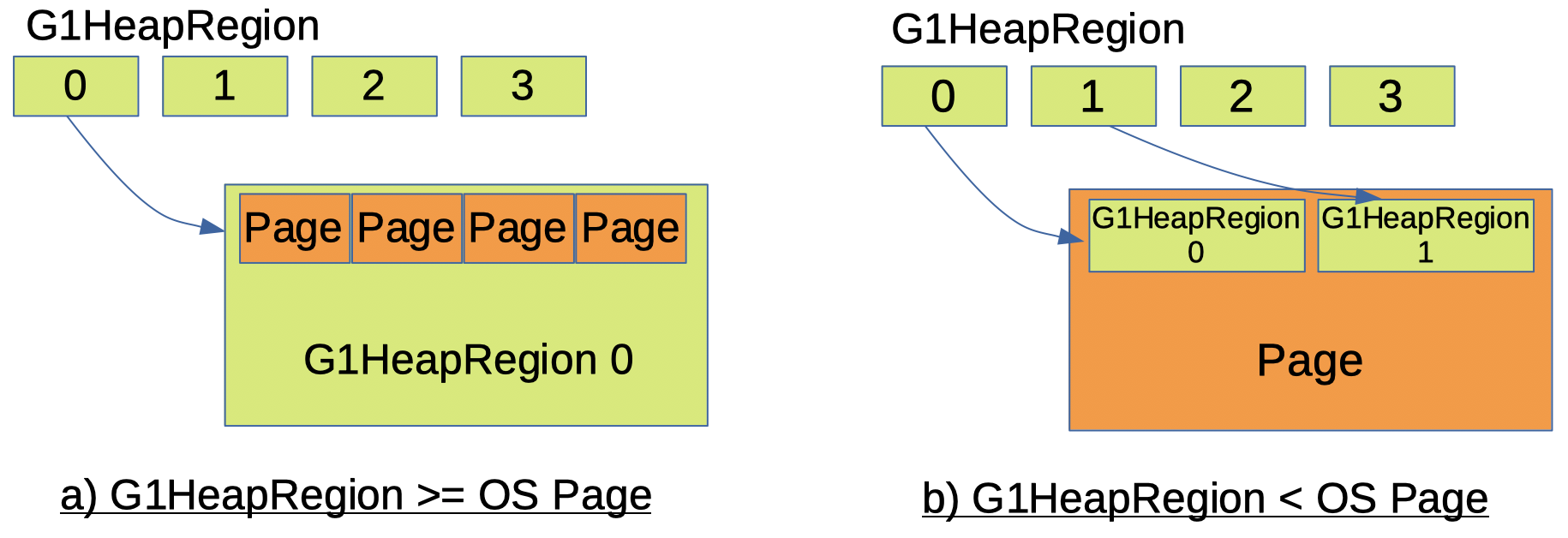
Someone may have a question about how G1 GC heap regions deal with OS pages. The granularity of NUMA id in G1 GC is the heap region which means one heap region is considered to have the same NUMA id for the heap region. And this is different from the granularity of OS which is page. It is straightforward if the OS page is smaller than the G1 heap region size. One G1 heap region will be consist of multiple OS pages. e.g. if the G1 heap region size is 1MB and the page size is 4KB, 256 pages will be used for one heap region. What happens if the G1 heap region size is smaller than the OS page size? In such a case, one large page will be used for multiple G1 heap regions. e.g. if the G1 heap region size is 1MB and the page size is 2MB, two pages will be used for two heap regions (Figure 2). Of course, for G1 heap region size and OS page size, one size should be multiple of the other.
NUMA-aware Memory Allocation
The basic heap initialization is ready, now let’s talk about how memory is allocated to the Java application.
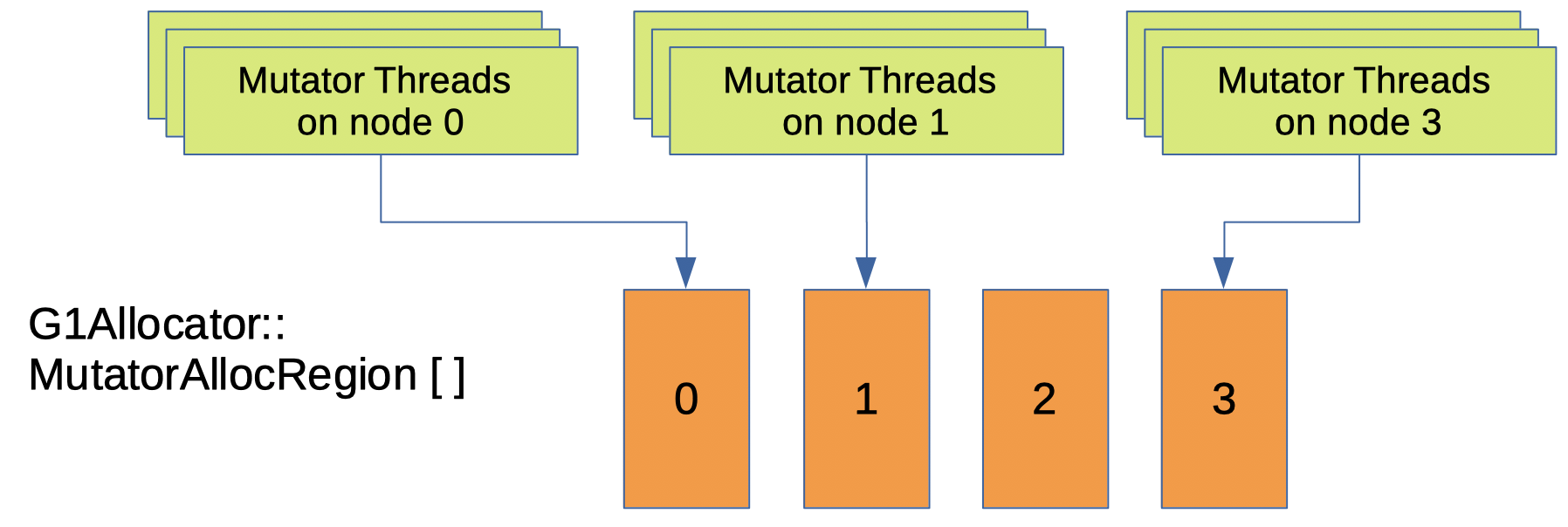
Before this change, when a Java thread requests memory to JVM, G1 GC will allocate memory from a single MutatorAllocRegion instance5.
Now, G1 GC has multiple MutatorAllocRegion, one instance per NUMA node. (Figure 3)
So when a Java thread requests memory to JVM, G1 GC will check the mutator(Java thread)’s NUMA node and then allocate memory from MutatorAllocRegion which has the same NUMA node.
NUMA-aware Surviving Object Allocations during Young Evacuation
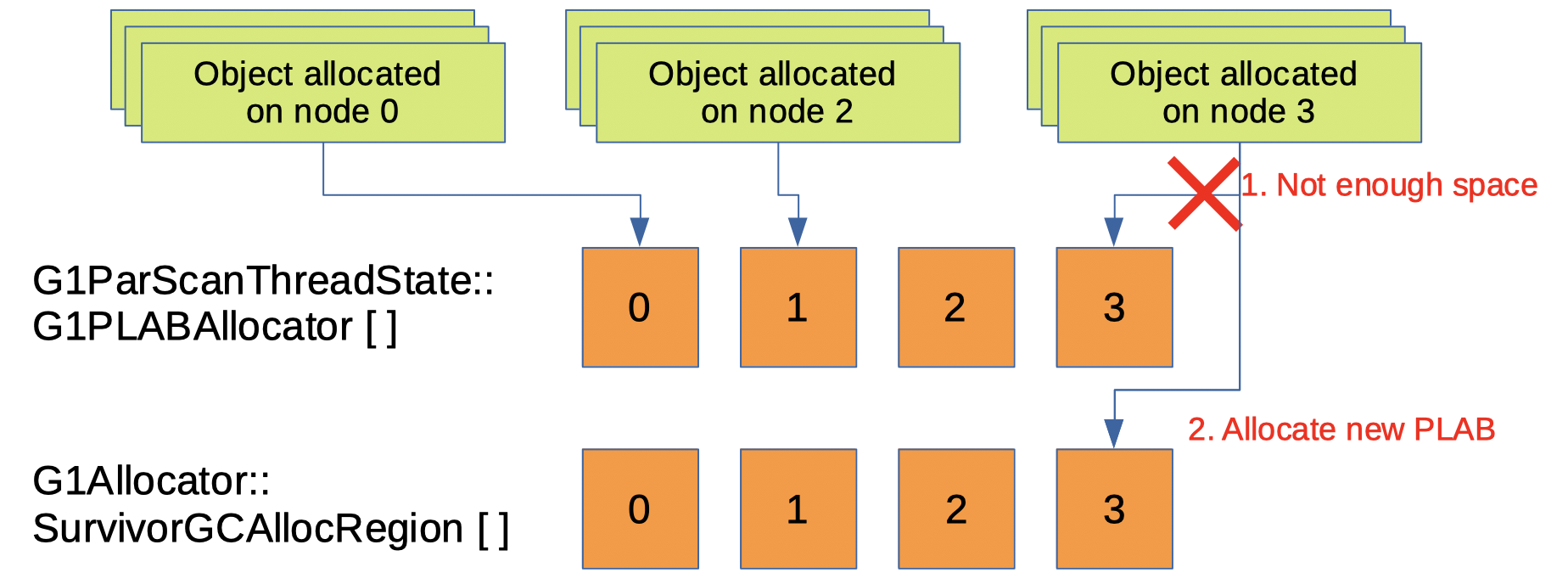
We apply the above concept to Survivor regions as well, G1 GC will have multiple SurvivorGCAllocRegion, one instance per NUMA node. Besides, there is another thing to consider. The addition is a buffer used when G1 GC copies surviving objects. This buffer is called PLAB (Promotion Local Allocation Buffer).
When young GC happens, G1 GC will copy surviving objects to the survivor regions using multiple GC threads6. Each GC thread has its own PLAB to allocate the surviving objects. Each PLAB is allocated from SurvivorGCAllocRegion. With PLAB, G1 GC can minimize synchronization delay to the SurvivorGCAllocRegion compared to directly allocating from SurvivorGCAllocRegion. With those two things added, surviving object allocations during young evacuation are now NUMA-aware. (Figure 4)
No NUMA-aware Processing for Old Generation
In the beginning, I mentioned the whole Java heap will be split evenly to active NUMA nodes but only explained the Young generation (Eden and Survivor regions). G1 GC manages the remainder, Old generation without NUMA node information.
Currently Old generation gets an empty heap region from the head of list without NUMA node information7. So there is only one instance of OldGCAllocRegion which is same as NUMA changes were introduced. And this will help balancing heap regions among NUMA nodes.
Actually there was another approach which was not accepted. That is keeping the NUMA node information when surviving objects are promoted to Old generation. However, this approach may consume heap regions on specific NUMA nodes which results in bad balancing heap regions among NUMA nodes. And this approach didn’t bring performance improvement. ParallelGC also doesn’t have NUMA-aware processing for Old generation because it didn’t bring performance improvement.
We will consider adding NUMA-awareness on Old generation in the future if there are visible benefits.
Logging
The logging for those newly added implementations are managed by numa tag. When you try -Xlog:gc*, the VM will print NUMA info level logs as well and if you are interested watching only NUMA related logs, -Xlog:numa*={log level} is what you need.
SpecJBB2015 results comparison
Let’s investigate the performance improvements this change yields.
We use SpecJBB20158 for this test. We compare the JDK-14 build 24 where JEP-345 has been integrated into with build 23 without this change to minimize the influence of other changes. Additionally, there are two more test results - from the latest LTS (Long Term Support) which is 11, and from the latest JDK which is 15.
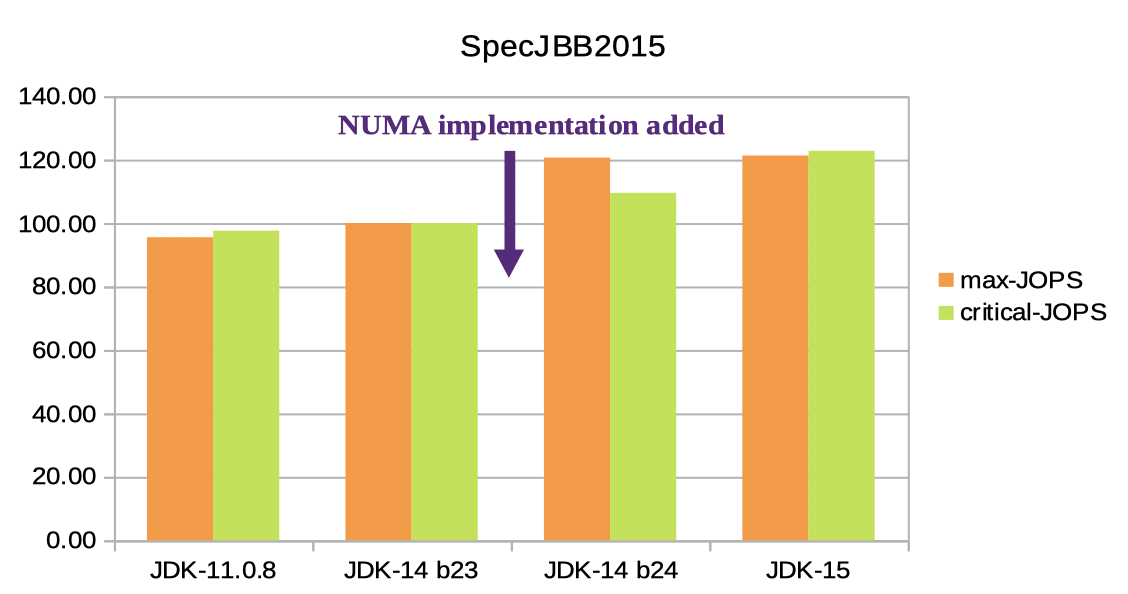
All runs were tested with 512GB Java heap size and UseNUMA option enabled on four NUMA nodes machine 9.
Both Max-jOPS and Critical-jOPS showed promising improvements between JDK-14 b23 and JDK-14 b24. Max-jOPS is improved by 20.64% and Critical-jOPS is improved by 9.52%. (what is Max-jOPS and Critical-jOPS)
Not related to NUMA changes but worth to mention is that newer JDK versions have better scores of Max-jOPS and Critical-jOPS than older JDKs.
The more NUMA nodes on a test system, the more improvements. Another thing to consider is if a Java application to test is setting a small Java heap size which is enough to be allocated from one NUMA node, we will not see any improvement. Simply because mutator threads on Java application and GC threads are hardly accessing non-local memories. e.g. if the testing host machine has 32GB of memory on two NUMA nodes, each node will have 16GB of memory. If a Java application is only using 1GB of memory, all memory can be allocated from one NUMA node so improvement will not happen in such case.
Lastly!
I explained what I implemented on G1 GC. Now you can try it out.
Update (2021-03-01)
Search depth was introduced to avoid too much unbalance among NUMA nodes. And it will provide less fragmentation and less delay when we traverse FreeRegionList. In the below example, G1 is requested to return memory from node 1 but the FreeRegionList already used many HeapRegions on node 1. So after searching 3 sets(=12 regions = # of NUMA nodes * search depth = 4 * 3) of regions, G1 will stop searching and then return the first region on the list.
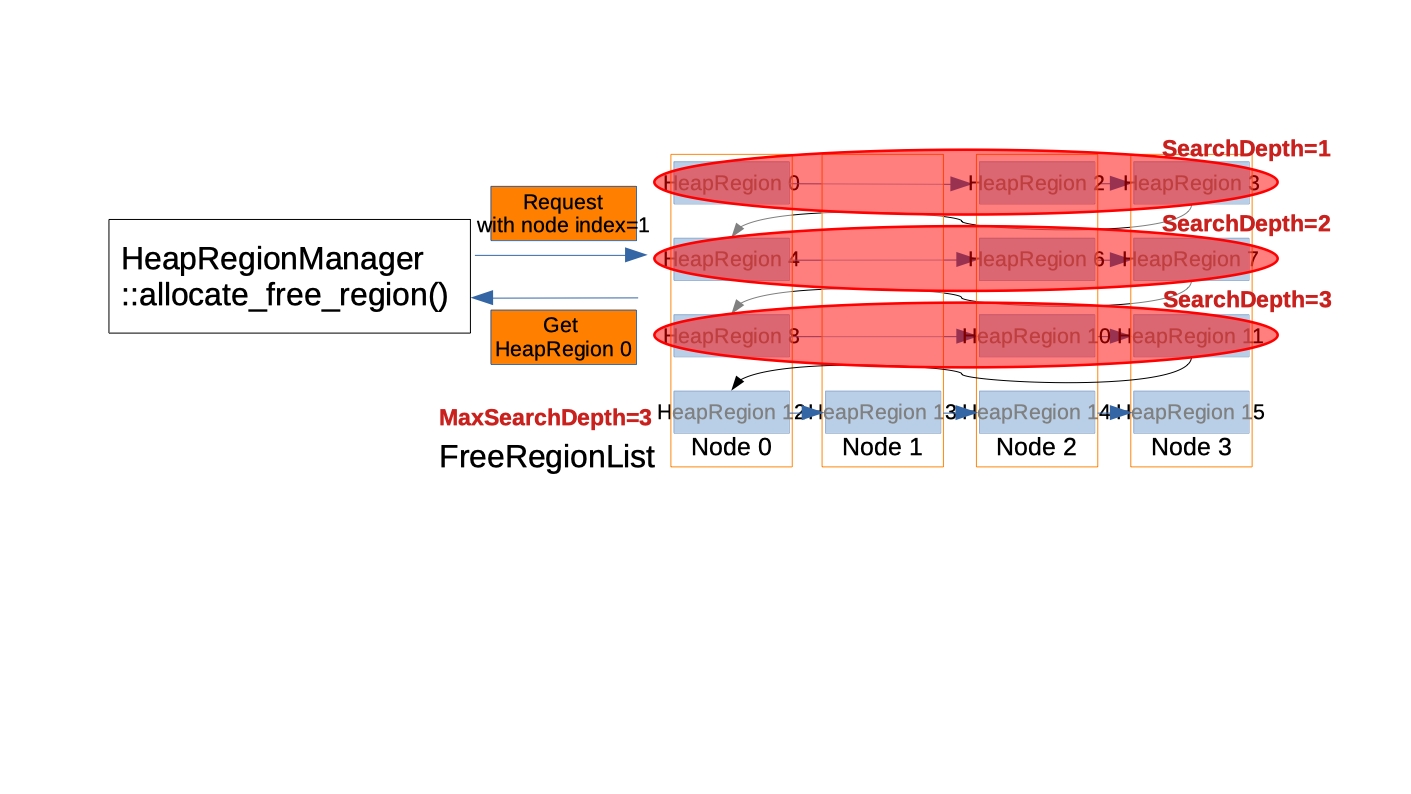
-
Implemented only on Linux ↩
-
numactl --hardware,
node distances:
node 0 1
0: 10 20
1: 20 10Memory Latency Checker v3.5,
Measuring idle latencies (in ns)…
Node 0 1
0 69.7 119.0
1 112.9 69.9 ↩ -
In some situations, there might be no performance difference, but generally we can expect some improvements. ↩
-
NUMA-interleaving is managed by
UseNUMAInterleavingoption which is automatically enabled whenUseNUMAis enabled. ↩ -
MutatorAllocRegionis an abstracted class to manage G1 heap region. ↩ -
The number of those GC threads are controlled by
-XX:ParallelGCThreads={number}. ↩ -
All G1 heap regions are allocated from a list called HeapRegionManager::FreeRegionList. And heap regions of Old generation are allocated without NUMA node information. ↩
-
SPEC® and the benchmark name SPECjbb® are registered trademarks of the Standard Performance Evaluation Corporation.
For more information about SPECjbb, see www.spec.org/jbb2015/ ↩ -
Full VM options
-Xmx512g -Xms512g -XX:+AlwaysPreTouch -XX:+PrintFlagsFinal -XX:ParallelGCThreads=48 -XX:ConcGCThreads=4 -XX:+UseG1GC -XX:+UseLargePages -XX:+UseNUMA -Xlog:gc*,ergo*=debug:gc.log::filesize=0 -XX:-UseBiasedLocking↩